Quro
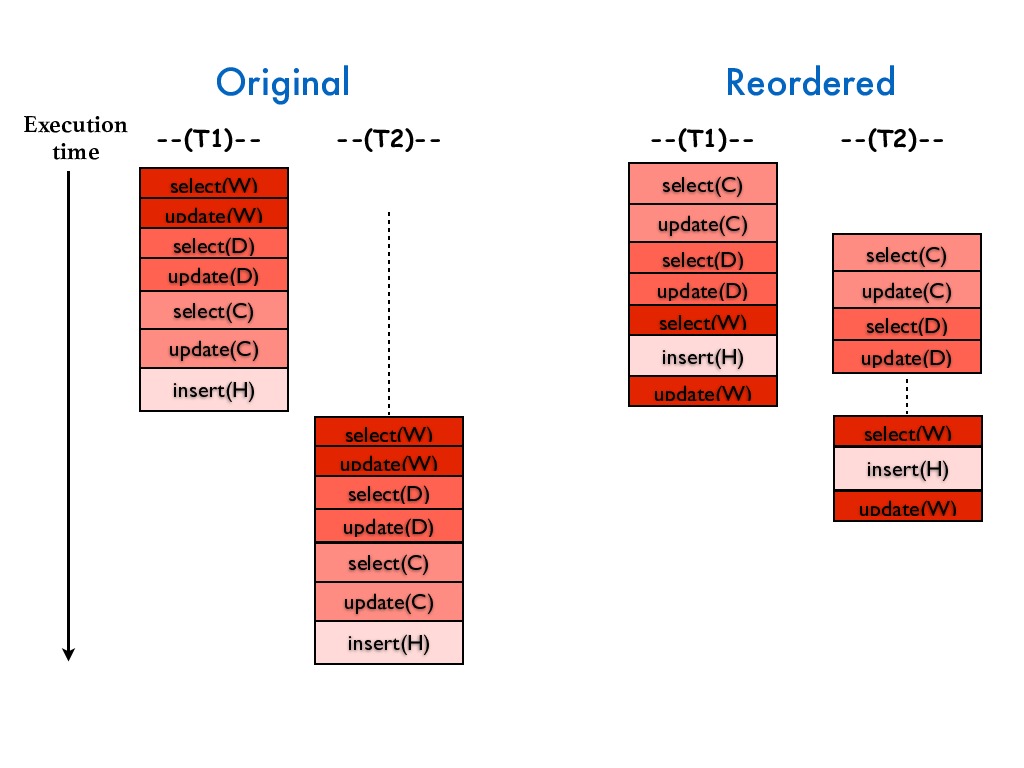
This is the project webpage for Quro, a query-aware compiler that automatically reorders
queries in database transactions to improve application performance.
On this page we provide instructions to run the experiments included in our VLDB 16
paper, along with link to the Quro source code.
Contact the Quro developers if you have any comments about Quro.
Sign up on the Quro users mailing list
to receive updates.
Logging on to the Quro virtual machine
- Make sure virtualbox is installed.
- Start the VM:
- Open virtualbox gui;
- Import the VM: File->Import Appliance, then choose the downloaded ova file to import;
- Start the VM:
Username: quro
Password: qurotest
- Instructions for logging on to the VM via ssh:
- Set the port number for the VM using GUI;
- Start the VM:
~$: vboxmanage startvm quro_test --type=headless for the full VM, or
~$: vboxmanage startvm quro_lite --type=headless for the lite VM;
- Ssh to the VM:
$ ssh -p 2345 quro@localhost
password: qurotest
What’s in the VM?
- The benchmarks (both original and QURO-generated implementations) evaluated in the paper. (source code on github)
- QURO built with clang libtool. (source code on github)
- A database (forked from DBx1000) and TPC-C benchmark to evaluate the performance of different concurrency control schemes. (source code on github)
- MySQL 5.5 database server. To check out the configurations for the server:
quro@ubuntu:~$ vi ~/.my.cnf
The full VM contains already-created databases for all benchmarks, complete llvm code that the quro code can be compiled; while the ligher VM requires user to create the database, and contains only executable quro binary.
Following are brief instructions to run each code with basic settings. For more detailed instructions, checkout the "QURO_readme" file under each code repository.
Reproducing the evaluation:
- Start MySQL server:
quro@ubuntu:~$ cd ~/mysql-5.5/mysql-5.5.45-linux2.6-x86_64/support-files
quro@ubuntu:~$ ./mysql.server restart
quro@ubuntu:~$ cd ~/dbt5
- Configure the benchmark:
- Open a configuration file, for example:
quro@ubuntu:dbt5$ vi src/scripts/configuration.example
- Specify the configurations, including benchmark name, type of transaction, running time, number of clients, etc.
- Compile and run:
- The script run_by_config.py will read the configuration file, then compile and run the workload.
quro@ubuntu:dbt5$ python run_by_config.py configuration.example
Errors of missing libraries can be ignored, as long as the make script is able to generate binaries under /home/quro/dbt5/bin/. Some library links are missing when running make for the first time, but the script will add those links to link.txt under proper directory and recompile.
- Build the database:
In both VMs, the databases for all benchmarks have already been created.
In the full VM, for the TPCC benchmark, data for 4 and 64 warehouses is provided. In the lite VM, only data for 4 warehouses is provided.
You can create your own database by following the instructions below.
To create the database:
quro@ubuntu:dbt5$ cd scripts/mysql
- TPCC:
quro@ubuntu:scripts$ ./tpcc-mysql-build-db for 4 warehouses or
quro@ubuntu:scripts$ ./tpcc-mysql-build-large-db for 64 warehouses
An error for procedure already being created may be expected... But this can be safely ignored.
- TPCE:
quro@ubuntu:scripts$ mkdir ~/DBT5_EGEN_DATA
quro@ubuntu:scripts$ ./dbt5-mysql-build-db -c ${NUMBER_OF_CUSTOMERS} -t ${NUMBER_OF_ACTICE_CUSTOMERS} -s ${SCALE_FACTOR} -w ${TRADE_DAYS}
For example,
quro@ubuntu:scripts$ ./dbt5-mysql-build-db -c 1000 -t 1000 -s 500 -w 5
- BID:
quro@ubuntu:scripts$ mkdir ~/BID_DATA
quro@ubuntu:scripts$ ./bid_datagen
quro@ubuntu:scripts$ ./bid-mysql-build-db
By default, in the full VM, the bidding benchmark uses 6400000 customers and 64 bidding items, and in the lite VM, 400000 customers and 4 bidding items. To change the data size:
quro@ubuntu:scripts$ vi bid_datagen.cpp
modify the scale factor, and recompile:
quro@ubuntu:scripts$ g++ bid_datagen.cpp -o bid_datagen
Results will be saved in ~/results/{BENCHMARK}_{CONFIGURATIONS}/. CONFIGURATIONS include transaction name, implementation type (original/reordered), number of server threads, total running time, etc. Under the directory, the performance related data (number of commits/aborts, total running time for each thread, etc) can be found in ${BENCHMARK}/${BENCHMARK}.out.
For a single run with a certain number of clients, the application will be running for 5 min, and then sleep for 2 min to wait for file writing and data collecting. The total running time depends on the number of runs. For example, if you specify "CONNECTIONS" in the configuration file to be the sequence "2 4 8 16", the script will run the workload for 4 runs, on 2, 4, 8, 16 clients. So altogether it takes 28 min to finish.
- Run the stored procedure implementation:
quro@ubuntu:scripts$ cd ~/dbt5
Comment out CMakeLists.txt line 170-175 and uncomment line 176-180 (to use source code Storeproc_TXNNAME.cpp instead of TXNNAMETxn.cpp), recompile and rerun the application.
- What to expect: The lite VM is expected to run on 16 processors and 32GB memory. The lack of computational resources will largely affect the results. Since the database and the clients are running on the same machine, it would be better to run experiments with no more than 8 clients ( which means 8 database connections). For TPC-C benchmark, when running 4 clients ( 4 database connections) on payment transaction, reordering should have ~2x throughput comparing to the original implementation.
To get the numbers showed in the paper, a large mahine is required. You are welcome to run the experiments on your own machine and compare the numbers.
Running QURO to reorder queries:
quro@ubuntu:~$ cd ~/llvm/test/
quro@ubuntu:test$ vi ${TRANSACTION}_freq.txt
Options for ${TRANSACTION} include payment, neworder, bid.
This file contains the profiling result of the ${TRANSACTION}. Each line shows the scaled multiplicative inverse of conflict index for each table. Larger the value, smaller the chance that this table is going to have data conflict. Feel free to modify this file to see how the reordering result changes.
quro@ubuntu:test$ ./quro_reorder.sh ${TRANSACTION}
The reordered transaction code will be in output.cpp under the same directory where you run the quro_reorder script.
An error of segmentation fault may be expected... But this can be safely ignored.
- Only quro binary is provided in the ligher VM, and a complete llvm source code is provided in the full VM.
checkout ~/quro/README.rd for instructions to compile and run quro on your own machine.
- Connecting to external ILP solvers is still under construction. The version of Quro on the provided VM uses a simple heuristic to reorder all statements instead of using an ILP solver, but it can generate input for ILP solver and let it compute the final order of queries/units. To use the external ILP solver,
checkout ~/ILPsolvers/code/lp_solve_5.5/quro/QURO_readme for instructions to run lpsolver, or
checkout ~/ILPsolvers/code/gurobi/QURO_readme for instructions to run gurobi.
Comparing to other concurrency control schemes:
quro@ubuntu:~$ cd ~/DBx1000/
- Configure the database:
quro@ubuntu:DBx1000$ vi config.h
To specify concurrency control schemes, change #define CC_ALG {ALGORITHM}, where ALGORITHM is either one of
NO_WAIT, DL_DETECT, MVCC, OCC.
NO_WAIT and DL_DETECT are two implementations of 2PL. NO_WAIT aborts the transaction when it touches a locked tuple, and DL_DETECT monitors wait-for graph and aborts one transaction upon finding a cycle. For more details, check out Xiangyao's paper Staring into the Abyss: An Evaluation of
Concurrency Control with One Thousand Cores.
To specify the total number of transactions to run for each thread, change #define MAX_TXN_PER_PART
To specify the number of database client, update #define THREAD_CNT
- To execute the original implementation under 2PL, copy the transaction file to the
benchmarksdirectory:
quro@ubuntu:DBx1000$ cp temp_transaction_file/tpcc_txn.cpp benchmarks/tpcc_txn.cpp
- To execute the reordered implementation under 2PL, copy the transaction file to the
benchmarksdirectory:
quro@ubuntu:DBx1000$ cp temp_transaction_file/reorder_tpcc_txn.cpp benchmarks/tpcc_txn.cpp
- Compile:
quro@ubuntu:DBx1000$ make
- Run:
quro@ubuntu:DBx1000$ ./rundb
The program will start the database, populate it and then run the transactions under specified concurrency control scheme.
What to expect: Each thread will run the number of transactions as specified in config.h.
When all threads finish, the following will be printed on the screen:
txn_cnt: total number of commited transactionsrun_time: total running time and throughput (txn_cnt/run_time)
The default configuration runs on 8 threads and 1000 transactions for each thread.
The program is expected to finish within seconds. Under the default setting,
the throughtput of the reordered implementation under DL_DETECT is ~2x than original,
and ~1.35x for NO_WAIT.
The throughput of the reordered implementation under DL_DETECT is ~2.5x
compared to OCC, and ~1.1x compared to MVCC.