Mobile and pervasive applications frequently rely on devices such as RFID antennas, light sensors, temperature sensors, motion sensors, etc. to provide them information about the physical world. These devices, however, are unreliable. They produce streams of information where portions of data may be
We are currently building a system called StreamClean. StreamClean is a system for correcting input data errors automatically using application defined global integrity constraints. Because it is frequently impossible to make corrections with certainty, we propose a probabilistic approach, where the system assigns to each input tuple the probability that it is correct.
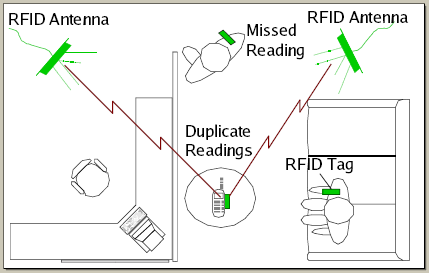
Imagine an RFID-based book tracking system deployed in a library. Such a deployment is similar to that shown in the figure above, except that RFID tags are attached to books and antennas are deployed on shelves and near tables. Every time a tag is in the vicinity of an antenna, the antenna detects the tag and produces an event. If a tag remains near an antenna, the antenna produces periodic events indicating the presence of the tag. With this deployment, librarians can see the location of each book at any time. The challenge is that RFID antennas are not reliable: they can fail to read a nearby tag or detect a tag that is relatively far away and also detected by another antenna. Antenna errors can cause users to receive erroneous information. If an antenna fails to detect a nearby book, and the book is misshelved, a librarian will not be notified about the problem. If multiple antennas detect the same book, a librarian may simultaneously receive information that the book is on the correct shelf and an alert that the book is misshelved. Such erroneous information can be at best annoying to users, and at worst discourage them from using the system.
Ideally, we would like the system to correct all input data errors. However, it is often not possible to correct data source errors with certainty. For instance, if two antennas detect the same book, it is not always clear which antenna is correct. We thus propose to correct input data probabilistically. When errors occur on input streams, we would like the results sent to applications to be annotated with the probability that they are correct. The system could, for example, indicate that there is a 20% chance the book is on the correct shelf, a 75% chance it is misshelved, and a 5% chance that it is lying on one of the tables. With this approach, an application can take into consideration the probabilities when processing the data. Whether it exposes these probabilities to the user depends on the application.
Such a system requires four pieces of functionality:
We propose to insert StreamClean between the data sources and the operators running at the stream processing engine. This enables StreamClean to detect and correct errors before any additional processing occurs. We assume that all input streams go to a central location running a single instance of StreamClean. Distribution issues are outside the scope of this project.

Last Modified at2006-07-20 09:44:21 Pacific Daylight Time