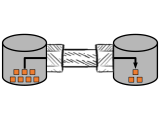
PipeGen allows users to automatically create an efficient connection between pairs of database systems. PipeGen targets data analytics workloads on shared-nothing engines, and supports scenarios where users seek to perform different parts of an analysis in different DBMSs or want to combine and analyze data stored in different systems. The systems may be colocated in the same cluster or may be in different clusters.
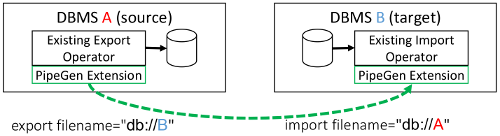
To achieve high performance, PipeGen leverages the ability of all DBMSs to export data into a common data format such as CSV or JSON. It automatically extends these import and export functions with efficient binary data transfer capabilities that avoid materializing the transmitted data on the file system. Our experiments show that PipeGen delivers speedups up to 3.8x compared with manually exporting and importing data across systems using CSV.
Using PipeGen is easy. First, create a configuration file for the database you wish to modify. For example, we modify the Myria DBMS using the following metadata (abbreviated for readability; see myria.yml):
name: Myria
version: 51
classPaths:
- build/libs/*
instrumentation:
classes: .*GradleWorkerMain
optimization:
classPaths:
- build/libs/myria-0.1.jar
datapipe:
import: ./gradlew -Dtest.single=FileScanTest test
export: ./gradlew -Dtest.single=DataSinkTest cleanTest test
Note that the configuration file requires two scripts:
An optional verification script may be specified to test the data pipe; if none is specified, both the import and export scripts are executed.
Finally, launch the PipeGen tool to add the data pipe to the DBMS:
java org.brandonhaynes.pipegen.PipeGen myria.yml
The PipeGen tool will execute in two phases: a redirection phase (where file system IO calls are redirected to a remote system) and an optimization phase (where the efficiency of text-oriented formats are increased). After execution, PipeGen will report one of the following:
The worker directory serves as a central registry for matching exporting and importing DBMSs. It must be active on a host available to each DBMS participating in a query. Launch the worker directory by executing the following command:
java org.brandonhaynes.pipegen.runtime.directory.WorkerDirectoryServer production
Once a DBMS has been augmented with a data pipe, results may be transmitted to another DBMS by specifying a reserved file name in the import or export filename. By default this format is dbms://[Name], where [Name] is the name of the remote system. This format may be altered by changing the format configuration entry located in /etc/pipegen/pipegen.yaml. For example, under Spark we might send data to Myria by executing the following query:
val rdd = sc.range(0, 10)
rdd.saveAsTextFile("dbms://Myria")
Contact the PipeGen developers or sign up for our mailing list to receive updates.
This work is supported in part by the National Science Foundation through grants IIS-1247469, IIS-1110370, IIS-1546083, and CNS-1563788; DARPA award FA8750-16-2-0032; DOE award DE-SC0016260; and gifts from the Intel Science and Technology Center for Big Data, Adobe, Amazon, Facebook, and Google.