Principled Cardinality Estimation
The UW database group has done several projects over the years which attempt to apply insights from the theory of databases to produce accurate cardinality bounds and estimates.
Quasi-Stable Cardinality Estimation
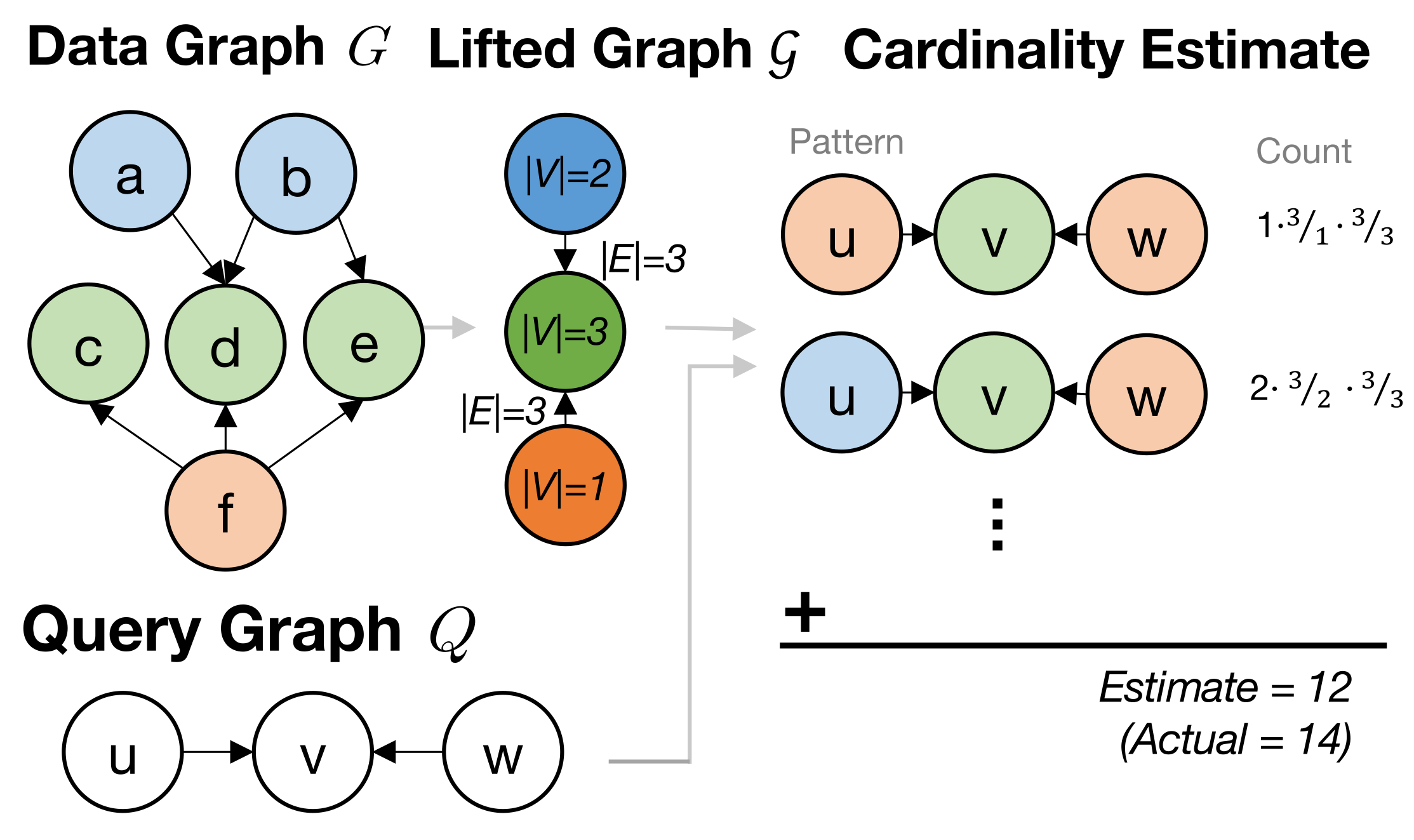
Project Motivation
Graph workloads pose a particularly challenging problem for query optimizers. They typically feature large queries made up of entirely many-to-many joins with complex correlations. This puts significant stress on traditional cardinality estimation methods which generally see catastrophic errors when estimating the size of queries with only a handful of joins. To overcome this, we propose COLOR, a frame- work for subgraph cardinality estimation which applies insights from graph compression theory to produce a compact summary that captures the global topology of the data graph. Further, we identify several key optimizations that enable tractable estimation over this summary even for large query graphs. We then evaluate several designs within this framework and find that they improve accuracy by up to 103� over all competing methods while maintaining fast inference, a small memory footprint, efficient construction, and graceful degradation under updates.
SafeBound
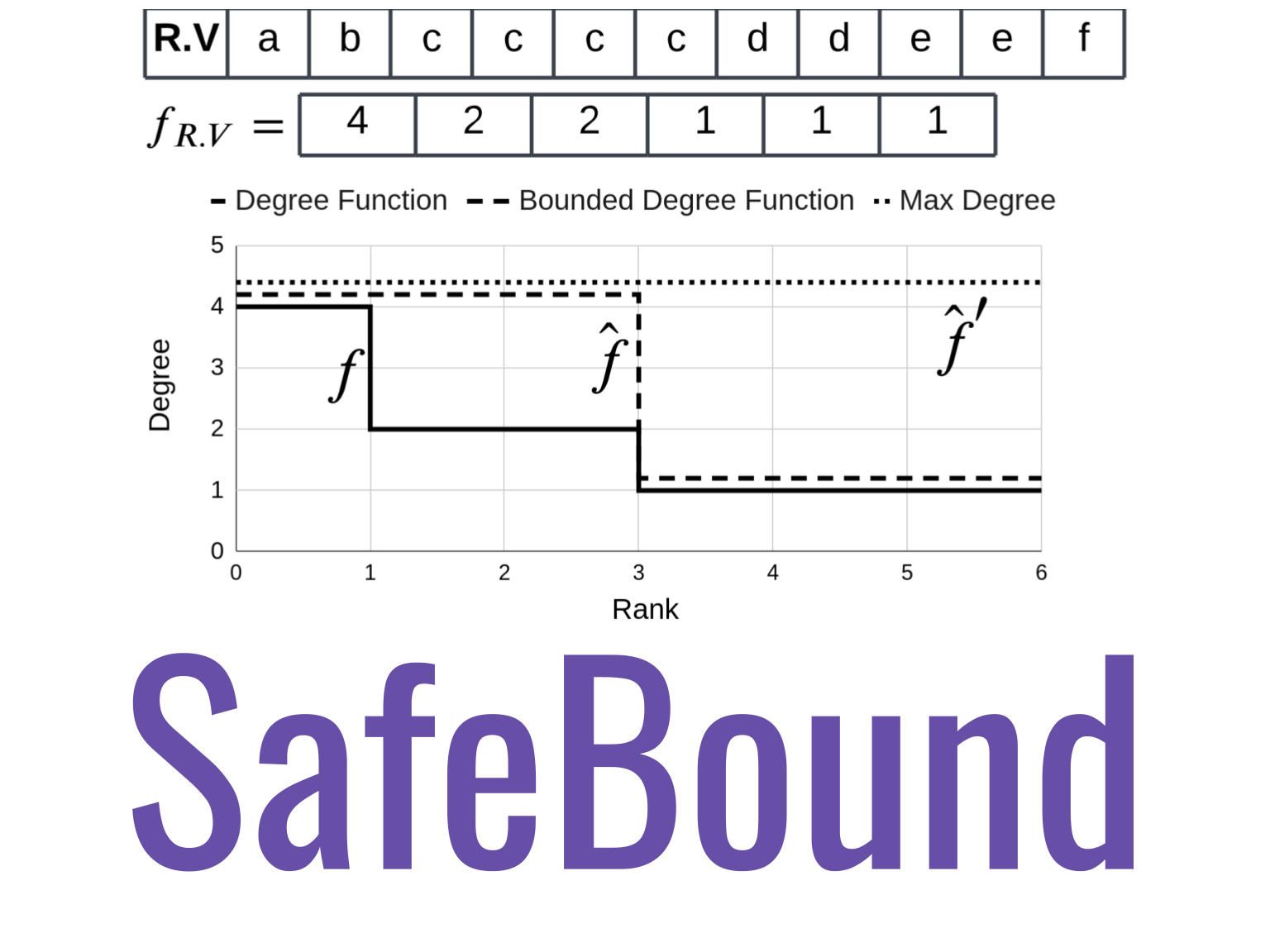
A practical system for generating provable cardinality bounds.
About SafeBound
Recent work has reemphasized the importance of cardinality estimates for query optimization. While new techniques have continuously improved in accuracy over time, they still generally allow for under-estimates which often lead optimizers to make overly optimistic decisions. This can be very costly for expensive queries. An alternative approach to estimation is cardinality bounding, also called pessimistic cardinality estimation, where the cardinality estimator provides guaranteed upper bounds of the true cardinality. By never underestimating, this approach allows the optimizer to avoid potentially inefficient plans. However, existing pessimistic cardinality estimators are not yet practical: they use very limited statistics on the data, and cannot handle predicates. In this project, we introduce SafeBound, the first practical system for generating cardinality bounds. SafeBound builds on a recent theoretical work that uses degree sequences on join attributes to compute cardinality bounds, extends this framework with predicates, introduces a practical compression method for the degree sequences, and implements an efficient inference algorithm. Across four workloads, SafeBound achieves up to 80\% lower end-to-end runtimes than PostgreSQL, and is on par or better than state of the art ML-based estimators and pessimistic cardinality estimators, by improving the runtime of the expensive queries. It also saves up to 500x in query planning time, and uses up to 6.8x less space compared to state of the art cardinality estimation methods.
Github
Our code for this project is on GitHub
Questions?
Contact Kyle Deeds
Acknowledgments
This work is supported in part by National Science Foundation grants (NSF IIS 1907997 and NSF-BSF 2109922) and a gift from Amazon through the UW Amazon Science Hub.
Pessimistic Query Optimization
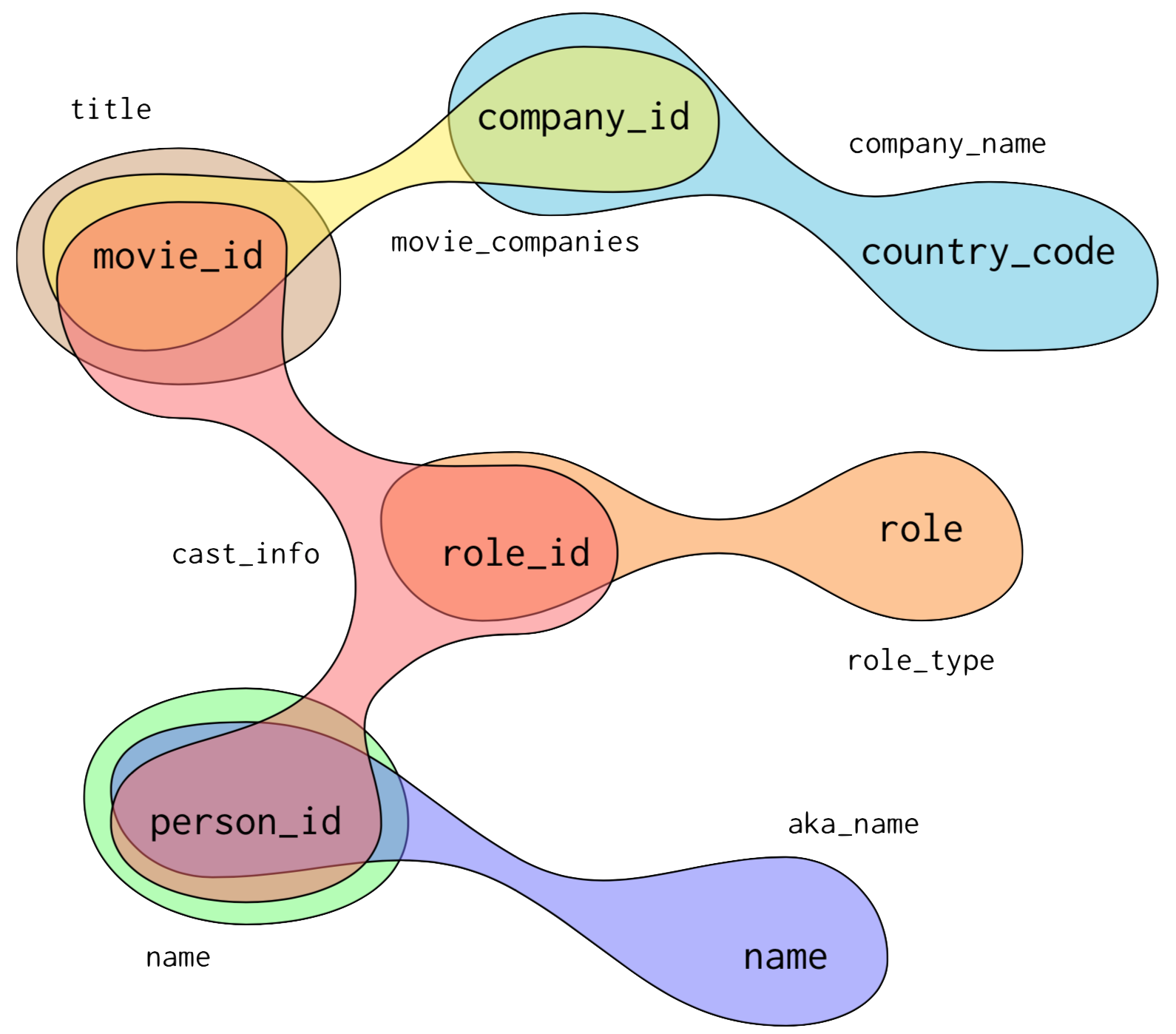
About Pessimistic Query Optimization
Despite decades of research, modern database systems still struggle with multijoin queries. In particular, cardinality estimation for queries with many tables. Our approach relies on generating theoretically guaranteed join cardinality upper bounds. In this work we introduce a novel approach leveraging randomized hashing and data sketching to tighten these bounds. Furthermore, we demonstrate that the bounds can be injected directly into the cost based query optimizer framework enabling it to avoid expensive physical join plans. We outline our base data structures and methodology, and how these bounds may be introduced to the optimizer’s parameterized cost function as a new statistic for physical join plan selection. We demonstrate a complex tradeoff space between the tightness of our bounds and the size and complexity of our data structures. In order combat this non-monotonicity, we introduce a partition budgeting scheme that guarantees monotonic behavior.
Questions?
Contact Walter Cai
Acknowledgments
This project is supported by NSF grants AITF 1535565 and III 1614738.