The VisualWorld Video Data Management Project
Our ability to collect and reason about video data at scale is revolutionizing how we interact with the world. To explore these ideas, we introduce VisualWorld, a collection of video data management projects ongoing in the University of Washington database group. VisualWorld projects explore video data management from a number of perspectives, including new approaches to VR and AR (LightDB and Visual Cloud), low-level video data storage especially in the context of machine learning (TASM and VSS), and evaluation of the performance and scalability of video data management systems (Visual Road).
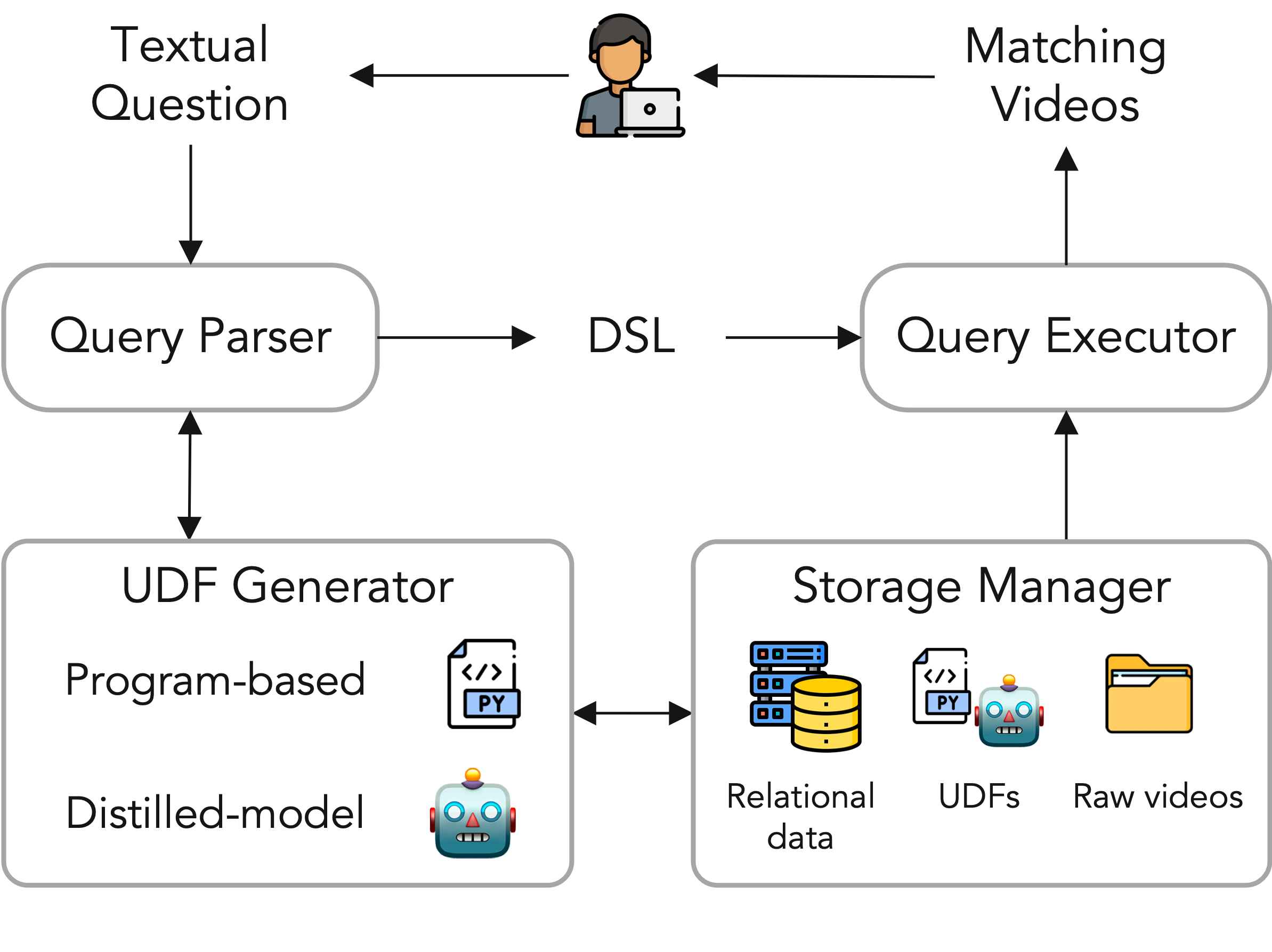
VOCAL-UDF
Complex video queries can be answered by decomposing them into modular subtasks. However, existing video data management systems assume the existence of predefined modules for each subtask. We introduce VOCAL-UDF, a novel self-enhancing system that supports compositional queries over videos without the need for predefined modules. VOCAL-UDF automatically identifies and constructs missing modules and encapsulates them as user-defined functions (UDFs), thus expanding its querying capabilities. To achieve this, we formulate a unified UDF model that leverages large language models (LLMs) to aid in new UDF generation. VOCAL-UDF handles a wide range of concepts by supporting both program-based UDFs (i.e., Python functions generated by LLMs) and distilled-model UDFs (lightweight vision models distilled from strong pretrained models). To resolve the inherent ambiguity in user intent, VOCAL-UDF generates multiple candidate UDFs and uses active learning to efficiently select the best one. With the self-enhancing capability, VOCAL-UDF significantly improves query performance across three video datasets.
Self-Enhancing Video Data Management System for Compositional Events with Large Language Models. Enhao Zhang, Nicole Sullivan, Brandon Haynes, Ranjay Krishna, Magdalena Balazinska. SIGMOD, 2025. Paper Technical Report Code Video

POLY-VOCAL
With the emerging ubiquity of video data across diverse applications, the accessibility of video analytics is essential. To address this goal, some state-of-the-art systems synthesize declarative queries over video databases using example video fragments provided by the user. However, finding examples of what a user is looking for can still be tedious. This work presents POLY-VOCAL, a new system that eases this burden. POLY-VOCAL uses multiple forms of user input to bootstrap the synthesis of a new query, including textual descriptions of the user's search and previously synthesized queries. Our empirical evaluation demonstrates that POLY-VOCAL significantly improves accuracy and accelerates query convergence compared with query synthesis from only user-labeled examples, while lowering the effort required from users.
Bootstrapping Compositional Video Query Synthesis with Natural Language and Previous Queries from Users. Manasi Ganti, Enhao Zhang, Magdalena Balazinska. HILDA @ SIGMOD, 2025. Paper

VOCALExplore
We introduce VOCALExplore, a system designed to support users in building domain-specific models over video datasets. VOCALExplore supports interactive labeling sessions and trains models using user-supplied labels. VOCALExplore maximizes model quality by automatically deciding how to select samples based on observed skew in the collected labels. It also selects the optimal video representations to use when training models by casting feature selection as a rising bandit problem. Finally, VOCALExplore implements optimizations to achieve low latency without sacrificing model performance. We demonstrate that VOCALExplore achieves close to the best possible model quality given candidate acquisition functions and feature extractors, and it does so with low visible latency (~1 second per iteration) and no expensive preprocessing.
VOCALExplore: Pay-as-You-Go Video Data Exploration and Model Building. Maureen Daum, Enhao Zhang, Dong He, Stephen Mussmann, Brandon Haynes, Ranjay Krishna, Magdalena Balazinska. PVLDB, 16 (13): 4188-4201, 2023. Paper Technical Report Code

EQUI-VOCAL
EQUI-VOCAL is a new system that automatically synthesizes queries over videos from limited user interactions. The user only provides a handful of positive and negative examples of what they are looking for. EQUI-VOCAL utilizes these initial examples and additional ones collected through active learning to efficiently synthesize complex user queries. Our approach enables users to find events without database expertise, with limited labeling effort, and without declarative specifications or sketches. Core to EQUI-VOCAL's design is the use of spatio-temporal scene graphs in its data model and query language and a novel query synthesis approach that works on large and noisy video data. Our system outperforms two baseline systems---in terms of F1 score, synthesis time, and robustness to noise---and can flexibly synthesize complex queries that the baselines do not support.
EQUI-VOCAL: Synthesizing Queries for Compositional Video Events from Limited User Interactions. Enhao Zhang, Maureen Daum, Dong He, Brandon Haynes, Ranjay Krishna, Magdalena Balazinska. PVLDB, 16 (11): 2714–2727, 2023. Paper Tech Report Code Video
EQUI-VOCAL Demonstration: Synthesizing Video Queries from User Interactions. Enhao Zhang, Maureen Daum, Dong He, Manasi Ganti, Brandon Haynes, Ranjay Krishna, Magdalena Balazinska. PVLDB, 16 (12): 3978–3981, 2023. Paper Code

VOCAL
Current video database management systems (VDBMSs) fail to support the growing number of video datasets in diverse domains because these systems assume clean data and rely on pretrained models to detect known objects or actions. Existing systems also lack good support for compositional queries that seek events consisting of multiple objects with complex spatial and temporal relationships. In this paper, we propose VOCAL, a vision of a VDBMS that supports efficient data cleaning, exploration and organization, and compositional queries, even when no pretrained model exists to extract semantic content. These techniques utilize optimizations to minimize the manual effort required of users.
VOCAL: Video Organization and Interactive Compositional AnaLytics (Vision Paper). Maureen Daum*, Enhao Zhang*, Dong He, Magdalena Balazinska, Brandon Haynes, Ranjay Krishna, Apryle Craig, Aaron Wirsing. CIDR, 2022. Paper
*Both authors contributed equally to the paper
VisualWorldDB
VisualWorldDB is a vision and an initial architecture for a new type of database management system optimized for multi-video applications. VisualWorldDB ingests video data from many perspectives and makes them queryable as a single multidimensional visual object. It incorporates new techniques for optimizing, executing, and storing multi-perspective video data. Our preliminary results suggest that this approach allows for faster queries and lower storage costs, improving the state of the art for applications that operate over this type of video data.
VisualWorldDB: A DBMS for the Visual World. Brandon Haynes, Maureen Daum, Amrita Mazumdar, Magdalena Balazinska, Alvin Cheung, and Luis Ceze. CIDR, 2020. Paper

LightDB
LightDB is a database management system (DBMS) designed to efficiently ingest, store, and deliver virtual reality (VR) content at scale. LightDB currently targets both live and prerecorded spherical panoramic (a.k.a. 360°) and light field VR videos. It persists content as a multidimensional field that includes both spatiotemporal and angular (i.e., orientation) dimensions. Content delivered through LightDB offers improved throughput, less bandwidth, and scales to many concurrent connections.
LightDB: A DBMS for Virtual Reality Video. Brandon Haynes, Amrita Mazumdar, Armin Alaghi, Magdalena Balazinska, Luis Ceze, Alvin Cheung. PVLDB, 11 (10): 1192-1205, 2018. Paper Code

Tile-Based Storage Management (TASM)
Modern video data management systems store videos as a single encoded file, which significantly limits possible storage level optimizations. We design, implement, and evaluate TASM, a new tile-based storage manager for video data. TASM uses a feature in modern video codecs called "tiles" that enables spatial random access into encoded videos. TASM physically tunes stored videos by optimizing their tile layouts given the video content and a query workload. Additionally, TASM dynamically tunes that layout in response to changes in the query workload or if the query workload and video contents are incrementally discovered. Finally, TASM also produces efficient initial tile layouts for newly ingested videos. We demonstrate that TASM can speed up subframe selection queries by an average of over 50% and up to 94%. TASM can also improve the throughput of the full scan phase of object detection queries by up to 2X.
TASM: A Tile-Based Storage Manager for Video Analytics. Maureen Daum, Brandon Haynes, Dong He, Amrita Mazumdar, Magdalena Balazinska. ICDE, 2021. Paper Code

VSS
VSS is a new file system designed to decouple high-level video operations such as machine learning and computer vision from the low-level details required to store and efficiently retrieve video data. Using VSS, users read and write video data as if it were to an ordinary file system, and VSS transparently and automatically arranges the data on disk in an efficient, granular format, caches frequently-retrieved regions in the most useful formats, and eliminates redundancies found in videos captured from multiple cameras with overlapping fields of view.
VSS: A Storage System for Video Analytics. Brandon Haynes, Maureen Daum, Dong He, Amrita Mazumdar, Magdalena Balazinska, Alvin Cheung, Luis Ceze. SIGMOD, 2021. Paper Tech Report Code

Visual Road
To accelerate innovation in video data management system (VDBMS) research, we designed and built Visual Road, a benchmark that evaluates the performance of these systems. Visual Road comes with a dataset generator and a suite of benchmark queries over cameras positioned within a simulated metropolitan environment. Visual Road's video data is automatically generated with a high degree of realism, and annotated using a modern simulation and visualization engine. This allows for VDBMS performance evaluation while scaling up the size of the input data.
Visual Road: A Video Data Management Benchmark. Brandon Haynes, Amrita Mazumdar, Magdalena Balazinska, Luis Ceze, Alvin Cheung. SIGMOD, 2019. Paper Code

Visual Cloud
Visual Cloud persists virtual reality (VR) content as a multidimensional array that utilizes both dense (e.g., space and time) and sparse (e.g., bit-rate) dimensions. It uses orientation prediction to reduce data transfer by degrading out-of-view portions of the video. Content delivered through Visual Cloud requires up to 60% less bandwidth than existing methods and scales to many concurrent connections.
VisualCloud Demonstration: A DBMS for Virtual Reality. Brandon Haynes, Artem Minyaylov, Magdalena Balazinska, Luis Ceze, Alvin Cheung. SIGMOD, 2017. Best Demonstration Honorable Mention. Paper
People


Maureen Daum







Acknowledgments
This work is supported by the NSF through grants IIS-2211133, CCF-1703051, IIS-1546083, CCF-1518703, and CNS-1563788; a grant from CISCO; DARPA award FA8750-16-2-0032; DOE award DE-SC0016260; a Google Faculty Research Award; an award from the University of Washington Reality Lab; gifts from the Intel Science and Technology Center for Big Data, Intel Corporation, Adobe, Amazon, Facebook, Huawei, and Google; and by CRISP, one of six centers in JUMP, a Semiconductor Research Corporation (SRC) program sponsored by DARPA.